

Ė―ÃØąŽŧðĩÄChatGPTĢšīóÕZŅÔÄĢÐÍĘĮÉķĢŋËüĩ―ĩŨÕĶđĪŨũĩÄĢŋ
Ô-
 2023-05-09 10:00:00
2023-05-09 10:00:00
-
 57092
57092
ąūÆŠÄŋä
Ā^AIĀLŪááĢŽChatGPTMŋÕģöĘĀĄĢÁÄĖėĄĒ·ŨgĄĒÎÄ°ļĄĒīúīaĄĄChatGPTĩÄđĶÄÜČįīËīóĢŽŌÔÖÁÓÚßBņRËđŋËķžÕJ Ą°ÎŌëxīóĩ―ÎĢëUĩÄAIēŧßhÁËĄĢĄą
ÔÚļÐŋŪChatGPTČįīËīóĩÄÍŽrĢŽČËŌēé_ĘžĶChatGPTĩÄđĪŨũÔĀíŪbÉúÁËšÃÆæĢšChatGPTĘĮĘēũáĢŋËüĩ―ĩŨĘĮČįšÎß\ÐÐĩÄĢŋÔõÓēÅÄÜ―zŧŽĩØÅcËüĶÔÄØĢŋ
ÏëŌŠÁË―âChatGPTĘĮĘēũáĢŽÐčŌŠęPŨĒËüąģááĩÄGPTÄĢÐÍĄĢGPTÄĢÐÍĘĮŌŧļöÓÉOpenAI ŅĩÁ·ĩÄīóÓïŅÔÄĢÐÍĄĢ

ŌŧĄĒīóÕZŅÔÄĢÐÍĘĮĘēũáĢŋ
īóÓïŅÔÄĢÐÍĢĻLarge Language ModelĢĐĘĮÖļÔÚšĢÁŋÎÄąūĘýūÝÉÏŅĩÁ·ĢŽÍĻđýÎÞžāķ―ĄĒ°ëžāķ―ŧōŨÔžāķ―ĩÄ·―Ę―ĢŽŅ§Ï°ēĒÕÆÎÕÍĻÓÃĩÄÓïŅÔÖŠĘķšÍÄÜÁĶĩÄÉîķČÉņūÍøÂįÄĢÐÍĄĢ
ÄÏÂDÖÐĢŽÎŌēŧëyŋīģöĢŽß@ÐĐīóÕZŅÔÄĢÐÍĩÄ ĒĩÓĩķžĘĮĩĮ§|Ģš
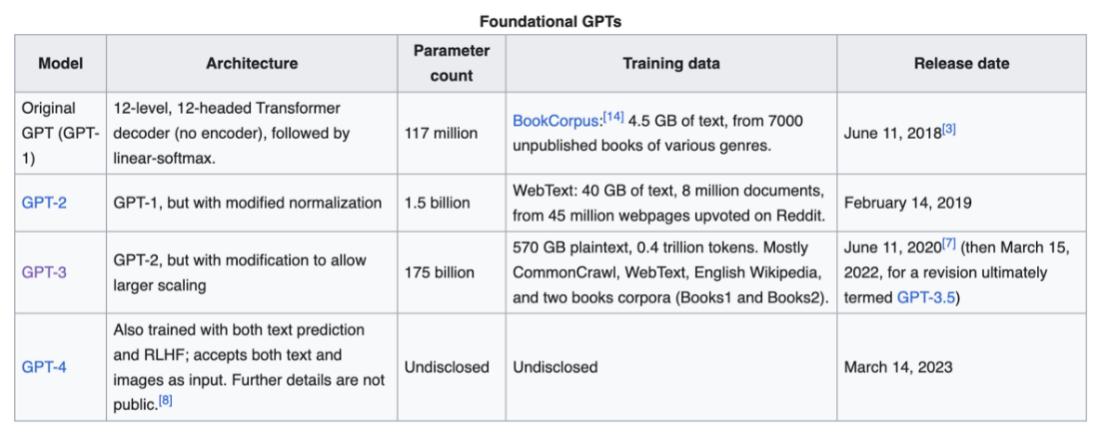
QČÝŌŨĀí―âĩÄÕf·ĻĢŽĄ°ŨxøÆÆČfūíĢŽÏÂđPČįÓÐÉņĄąÔÚŌŧķĻŌâÁxÉÏ·īÓģÁËīóÕZŅÔÄĢÐÍĩÄß\ŨũÄĢĘ―ĄĢÔÚšĢÁŋÎÄąūĩþÉÏÓūĘĮŨxÁËČf|øžŪĢŽÎüĘÕÁËīóÁŋĩÄÖŠŨRĢŽÔÚīËŧųĩAÉÏūÍŋÉŌÔ°īÕÕÓÃôĩÄÐčĮóßMÐÐŧØīðĄĒŨũĄĒŋ―YÅc·ÖÎöĄĢ
īóÕZŅÔÄĢÐÍÔÚ―ß^ĖØķĻÓūááŋÉŌÔ ÆóI§íŌâÏëēŧĩ―ĩÄŋÉÄÜÐÔĢš
| 1ĄĒpÉŲČËđĪÚÓšÍģÉąū |
īóÓïŅÔÄĢÐÍÄÜđŧČÃÆóŌĩÔÚ·ĒÕđđýģĖÖÐĘĩÏÖŨÔķŊŧŊĢŽČįđËŋÍ·þÕĄĒÄÚČÝīīŨũĄĒÆÛÕĐžėēâĩČĢŽÕâēŧ―öÄÜđŧ―ĩĩÍČËÁĶÓëĘąžäģÉąūĢŽŧđÄÜ―ŦÔąđĪīÓļßÖØļīķČĩÄđĪŨũÖÐ―â·ÅģöĀīĢŽīÓĘÂļüÐčŌŠČËĀāŨĻŌĩÖŠĘķĩÄÖØŌŠđĪŨũĄĢ |
| 2ĄĒĖáļßŋÍôMŌâķČ |
ŧųÓÚīóÓïŅÔÄĢÐÍĩÄÁÄĖėŧúÆũČËēŧ―öÄÜđŧΊŋÍŧ§ĖáđĐČŦĖėšōĩÄ·þÕĢŽŧđÄÜÍĻđýīĶĀíīóÁŋĩÄĘýūÝĀīÁË―âŋÍŧ§ĩÄÐÐΊšÍÆŦšÃĢŽīÓķøĖáđĐļöÐÔŧŊ·þÕĄĢ |
| 3ĄĒĖáđĐQēßĩÄŨžī_ÐÔ |
īóÕZŅÔÄĢÐÍĶīóÁŋĩþĩÄĖĀíĢŽÄÜōŨÆóIŅļËŲÄŅ}ësĩÄĩþžŊÖÐĖáČĄÐčĮóĢŽÄķøĖáļßß\ IЧÂĘĢŽļüŋėĩØ―âQî}ĢŽKŨöģöļüŨžī_ĩÄÉĖIQēߥĢ |
| 4ĄĒĖáļßČÎÕĩÄŨžī_ÐÔ |
īóÐÍÕZŅÔÄĢÐÍÄÜōĖĀíīóÁŋĩÄĩþĢŽÕâĩžÖÂÔĪēâšÍ·ÖĀāČÎÕĩÄŨžī_ÐÔĖáļߥĢÕâÐĐÄĢÐÍĀûÓÃÕâÐĐÐÅÏĒĀīŅ§Ï°ÄĢĘ―šÍđØÏĩĢŽÕâÓÐÖúÓÚËüÃĮŨöģöļüšÃĩÄÔĪēâšÍ·ÖŨéĄĢ |
ĩŦÎŌēŧĩÃēŧģÐÕJīóÕZŅÔÄĢÐÍÍŽÓīæÔÚÖøŌŧÐĐąŨķËĢš
| 1ĄĒÕJÖŠđ úÓÐÏÞ |
īóÕZŅÔÄĢÐÍĩÄÄÜÁĶĘÜÏÞÓÚËüĩÄÎÄąūÓūĩþĢŽß@ŌâÎķÖøËüo·ĻĀí―âÓūĩþŌÔÍâĩÄÎÄąūĢŽČįÕ{ÐÝĄĢËüOÓÐŋÉÄÜ―ÓÓ|ĩ―ĖžŲÐÅÏĒĄĒ·NŨåĄĒÐÔešÍÐÔĩÄÆŦŌĩČÎÄąūÓūĢŽß@þ§ÖÂīóÕZŅÔÄĢÐÍŪbģö·NŨåÖũÁxŧōÐÔeÆįŌĩÄÔuÕĄĢ |
| 2ĄĒÝČëtokenÓÐÏÞ |
ÃŋīóÕZŅÔÄĢÐÍĩÄČīæĘĮÓÐÏÞĩÄĢŽËųŌÔËüÖŧÄÜ―ÓĘÜŌŧķĻĩÁŋĩÄtokenŨũ ÝČëĄĢĀýČįĢŽChatGPTĩÄÏÞÖÆĘĮ4096ĢĻīóžs3000Ô~ĢĐĢŽČįđûģŽß^ß@ÏÞķĻĢŽGPTūÍo·ĻĶÝČëŨũģö·īŠĄĢ |
| 3ĄĒÏĩ―yģÉąūļß |
īóÐÍÕZŅÔÄĢÐÍĩÄé_°lšÍÓūķžÐčŌŠīóÁŋÍķŲYĢŽ°üĀĻÓËãCÏĩ―yĄĒČËÁĶŲYąūšÍëÁĶĄĢþđĀÓĢŽChatGPT10ÝĩÄÓūĢŽHëŲMģÉąūūÍļßß_1200ČfČËÃņÅĢŽß@KēŧĘĮëSąãŌŧÆóIÄÜōģÐúĩÃÆðĩÄĄĢ |
| 4ĄĒ·šŧŊÄÜÁĶČõ |
·šŧŊÄÜÁĶÖļCÆũWÁËã·ĻĶÐÂõrÓąūĩÄßmŠÄÜÁĶĄĢWÁĩÄÄŋĩÄĘĮWĩ―ë[šŽÔÚĩþąģááĩÄŌÂÉĢŽĶūßÓÐÍŽŌŧŌÂÉĩÄWÁžŊŌÔÍâĩÄĩþĢŽ―ß^ÓūĩÄūW―jŌēÄÜ―oģöšÏßmĩÄÝģöĄĢīóÕZŅÔÄĢÐÍëmČŧŋÉŌÔÔÚķāČÎÕÉÏąíŽFģöÉŦĢŽĩŦĘĮËüŌēČÝŌŨĘÜĩ―ÝČëĩÄÓ°íķøÝģöēŧšÏĀíŧōÕßåeÕ`ĩÄČČÝĄĢ |
ÔÚÁË―âÁËīóÕZŅÔÄĢÐÍááĢŽÎŌūāGPTĩÄđĪŨũÔĀíÓÖßMÁËŌŧē―ĄĢ
ķþĄĒGPTąģááĩÄŠÓÃßÝ
GPTĩÄČŦģÆĘĮĄ°Generative pre-trained transformerĄąĢŽ·ŌëŌŧÏÂūÍĘĮĄ°ŧųÓÚTransformerĩÄÉúģÉĘ―ÔĪŅĩÁ·ÄĢÐÍĄą ĄĢŨÎŌ°Ņß@ÐĐÔ~ēð·ÖíŋīĢš
1ĢĐĄ°GenerativeĄą
Ą°GenerativeĄąÖļß@ÄĢÐÍūßäÉúģÉŨÔČŧÕZŅÔÎÄąūĩÄđĶÄÜĄĢŌēūÍĘĮÕfĢŽß@ÄĢÐÍÄÜōÉúģÉŌŧķÎČČÝĢŽßÄÜŨÄãŋīķŪĄĢąČČį―oËüŨęPæIÔ~ĢŽÄÜōÍĻß^ß@ÐĐęPæIÔ~ŨÔÓÉúģÉŌŧķÎÔŧōÕßŌŧÆŠÎÄÕÂĄĢ
2ĢĐĄ°pre-trainedĄą
Ą°pre-trainedĄąŌâ Ą°îAÏČÓūšÃĩÄĄąĄĢŌŧ°ãíÖvĢŽÔÚŠÓÃß@·NžžÐgrĢŽþÐčŌŠÏČĒīóÁŋĩÄÎÄąūĩþÝČëĩ―ÄĢÐÍÖÐÓūĢŽŨÄĢÐÍÔÚŌŧķĻģĖķČÉÏÕÆÎÕÁËÕZŅÔĩÄÕZ·ĻŌtšÍąíß_·―Ę―ĢŽß@ĖáĮ°ÝČëßMÐÐÓūĩÄß^ģĖūÍąŧ·Q îAÓūĄĢ
3ĢĐĄ°transformerĄą
ŨîšóËĩĩ―Ą°transformerĄąĢŽÕâĘĮGoogle ĩÄŅÐūŋÕßÔÚĄķAttention Is All You NeedĄ·ÖÐĖáģöĩÄļÅÄîĢŽÎŌÃĮŋÉŌÔÏČ―ŦËüžōĩĨĀí―âΊĄ°ŨŠŧŧÆũĄąĄĢTransformerĩÄŧųąūÔĀíĘĮEncoderĢĻūīaĢĐšÍDecoderĢĻ―âīaĢĐĢŽŌēūÍĘĮÏČĒÝČëĩÄČČÝÞDQ ÓËãCÄÜĀí―âĩÄČČÝĢŽÔŲĒÓËãCĀí―âĩÄČČÝÞDQ ÎŌČËîÄÜĀí―âĩÄČČÝĄĢ
īð°ļđĀžÆŌēÃŧÉķÕųŌéĢš―ášÏÆŧđûÅÔąßĩÄĄ°Ōŧ―ïĄąšÍĄ°ÐÂŪbÆ·ĄąūÍÄÜČ·ķĻÔÚēŧÍŽÉÏÏÂÎÄÖÐĩÄĄ°ÆŧđûĄąīúąíÁËĘēÃīšŽŌåĄĢķøGPTÄÜđŧĀí―âÎŌÃĮĘäČëĩÄÄÚČÝĢŽđØžüŌēÔÚÓÚīËĄĢTransformerÔÚąāÂëšÍ―âÂëĩÄŧųīĄÉÏĢŽŌýČëÁËĄ°Multi-headed AttentionĢĻķāÍ·ŨĒŌâÁĶĢĐĄąĩÄļÅÄîĄĢķāÍ·ŨĒŌâÁĶūÍĘĮΊÁËČÃÄĢÐÍÔÚīĶĀíĘäČëĘäģöĩÄÄÚČÝĘąĢŽļüđØŨĒÄÚČÝÖÐĩÄÄģļöŧōÄģžļļöīĘÓïĢŽēĒķÔËüÃĮ―øÐОÓČĻīĶĀíĢŽīÓķøÍÆķÏÆäŨžČ·šŽŌåĢŽĘĩÏÖÉÏÏÂÎÄŅ§Ï°ĄĢ
ÓÃŌŧūäÔŋ―YÉÏÃæÖvĩÄČČÝĢŽūÍĘĮĄ°GPTÄÜŨxķŪÄãÕfĩÄÔÁËĄąĄĢ
žČČŧķŪÁËĖáĩÄČČÝĢŽÄĮ―ÓÏÂíGPTÓÖĘĮÔõÓŧØīðģöÄãÏëŌŠĩÄīð°ļĩÄÄØĢŋ
Į°ÃæÎŌÖvÁËGPTĘĮĄ°îAÏČÓūšÃĩÄĄąĢŽËųŌÔŪËüĀí―âÁËÄãÏëŌŠĘēũáÖŪááĢŽąãþŨÔÓßxņŪÏÂŨîßmšÏĩÄŌŧČČÝĢŽČŧááēŧÍĢĩØÔŲÝČëĄĒÝģöĢŽŨî―KÉúģÉŌŧķÎÍęÕûĄĒūßÓÐļßÆĨÅäķČĩÄČČÝĄĢ
ĀýŨÓĢšĮëļøÎŌÃčĘöŌŧļöÎũđÏ ĩÚŌŧīÎĘäČëĢšĮëļøÎŌÃčĘöŌŧļöÎũđÏ ĘäģöĢšÎũđÏ ĩÚķþīÎĘäČëĢšĮëļøÎŌÃčĘöŌŧļöÎũđÏĢšÎũđÏ ĘäģöĢšÎũđÏĘĮ ĩÚČýīÎĘäČëĢšĮëļøÎŌÃčĘöŌŧļöÎũđÏĢšÎũđÏĘĮ ĘäģöĢšÎũđÏĘĮŌŧÖÖ ĄĄ ĩÚNīÎĘäČëĢšĄĄ ĘäģöĢšĄĄ
Ũî―KģĘŽFŌÔÏÂČČÝĢš
ČýĄĒČįšÎŨChatGPTēŧÕfUÔĢŋ
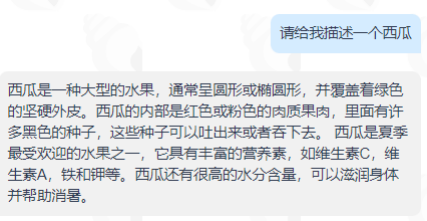
ÄĮũáĢŽĀí―âÁËChatGPTž°GPTÄĢÐÍĩÄß\Ðз―Ę―ĢŽËüūÍÄÜÕæÕý ÎŌËųÓÃáĢŋīð°ļï@ĘūĘĮ·ņķĻĩÄĄĢšÜķāČËþą§ÔđĢŽËüĩÄŧØīðšÜŋÕ·šĢŽÓÐrÉõÖÁþģöåeĄĢ
ŪČŧĢŽČËđĪÖĮÄÜŋÉŌÔĀí―âČËîĩÄÕZŅÔĢŽĩŦŋÉÄÜßēŧÄÜūŦŨžĀí―âČËîĩÄÄŋĩÄĢŽËųŌÔģÉđĶĩÄČËC―ŧŧĨēÅþĩÃĩ―ÎŌÏëŌŠĩÄīð°ļĢŽŌēūÍĘĮÕfGPTß@îÄĢÐÍūÍÏņÎŌĩÄÎïŌŧÓĢŽÄÜō ķŪÎŌÕfĩÄÔĢŽĩŦĮ°ĖáĘĮÎŌÐčŌŠļúËüĄ°šÃšÃÕfÔĄąĄĢ
íŋīŌŧĀýŨÓĢšÕ―é―BŌŧÏÂČAÉ―ĄĢĢĻPSĢšąūÎÄËųÓÐīðĢŽūųĀīŨÔėøĩĀĩÄOpenAIēåžþĢšÉņÆæÐĄšĢÂÝĢĐ


ÄÉÏÃæÉDÆŽÖÐŋÉŌÔ°lŽFĢŽÎŌĩÄĖáĘūÔ~ēŧÍŽĢŽÐĄšĢÂÝ―oģöĩÄŧØīðŌēēŧÍŽĄĢÄĮÎŌŠÔČįšÎĖáĢŋß@ŅYŌýÓÃģĢĮāĀÏŋ―YķøģÉĩÄŌŧĖáĘūÔ~ÄĢ°åĢĻÓHy·ĮģĢÓÐЧĢĐĢš

ÍĻß^ß@žžĮÉĢŽÎŌŽFÔÚŋÉŌÔļÄŌŧÏÂÉÏÃæĩÄĖáĘūÔ~Ģš
Ą°žŲČįÄãĘĮŌŧÃû§ß[ĢŽŽFÔÚÄãŌŠ§Ōŧ10ČËĩÄÂÃß[FĮ°ÍųČAÉ―ĢŽÕ―oŌŧ·ÝČAÉ―ĩÄÖv―âÔ~ĄĢÕŨĒŌâĢŽŌō ÂÃß[FÖÐÓÐÐĄÅóÓŅĢŽËųŌÔÖv―âÔ~ÕÓÃÉúÓÓÐČĪĩÄČČÝ―MŋĢŽŨîšÃßÄÜžÓŌŧÐĐđĘĘšÍĀýŨÓĄĢĄą

ŋÖŪĢŽÎŌÆÚīýÖøČËîĶŨÔČŧÕZŅÔĩÄĖĀížžÐgß_ĩ―ŌŧķĻģĖķČrĢŽß@ÐĐČËđĪÖĮÄÜĩÄŧØŅ}Ų|ÁŋÄܧ―oÎŌļüīóĩÄó@ÏēĢŧÔÚÁíŌŧ·―ÃæĢŽĶÓÚËüĩÄŧØīðĢŽÎŌŌēŌŠÓÐŧųĩAĩÄąæeÄÜÁĶĄĢ
Á_ÏčĀÏÔøÕfĢšĄ°ČËļúČËđĪÖĮÄÜŨîīóĩÄēŧÍŽĢŽÔÚÓÚČËģýÁËÓÐĀíÐÔßÓÐļÐĮéĄĢÎŌÓĀßhēŧÓÃúÐÄËüþČĄīúÎŌĢŽŌō ÎŌĘĮČËĢŽĘĮČfÎïÖŪė`ĄĢĄąËųŌÔĢŽÎŌēŧHŌŠ°ŅChatGPTŌŧîĩÄČËđĪÖĮÄÜŠÓÃĩ―OÖÂĢŽģä·ÖČĨíą§ËüĢŽßŌŠÓūŨÔžšŨũ ČËîÔÉúĩÄĄĒēŧŌĀŲČΚÎđĪūßĩÄŧųĩAÄÜÁĶĄĒËžūSÄÜÁĶŌÔž°ÐÂÄÜÁĶĄĢ


-

-
ėøĩĀŪbÆ·
ėøĩĀé_Ôī°æ ėøĩĀÆóI°æ ėøĩĀÆėÅ°æ ėøĩĀIPD°æ -
šËÐÄđĶÄÜ
ŪbÆ·đÜĀí íÄŋđÜĀí Ų|ÁŋđÜĀí ЧÄÜđÜĀí -
ĘđÓÃÎÄn
ŧųąū°æĘÖÔ ÆóI°æĘÖÔ ÆėÅ°æĘÖÔ IPD°æĘÖÔ é_°lÖÐÐÄĘÖÔ -
ÍÖúÖÐÐÄ
ŧý·Öīð ģĢŌî} ÕŊ―ŧÁũ ĘđÓÃŌîl Gitee GitHub -
ęPÓÚÎŌ
ęPÓÚÎŌ ėøĩĀÜžþ ŨîÐÂÓB ėøĩĀŧîÓ -
ėøĩĀÉį ^
ėøĩĀēĐŋÍ ·e·ÖÅÅÐÐ ·e·ÖÉĖģĮ ėøĩĀøÔš -
ÂÏĩ·―Ę―
ÂÏĩČËĢšķĄÖĨ ëÔĢš17663906485 ÎĒÐÅĢš17663906485 Q QĢš1481227768ąąūĐĄĒÉÏšĢĄĒÉîÛÚ·Öēŋ



ÍęÉÆÐÅÏĒÁėČĄíÄŋđÜĀíĀņ°ü







